.png)
2025年8月5日にOpen AI社が、自分のパソコンを使用して動かすことができるChat GPTの新しいAI実行用エンジン(以降、「モデル」と呼びます)を公開しました。
OpenAI社がこのようにモデルを公開したことは、OpenAI社の高品質な大規模言語モデル(以降、「LLM」と呼びます)でセキュリティ面を考慮したシステム開発が出来るようになる点で、AIビジネスとっては非常に大きな発表と考えています。
今回はシリーズ化し、開発実践編と実運用検討編の2つに分けて記事を公開します。
今回の開発実践編では、アプリケーションの実装を通してこのモデルの特徴をつかみます。
次回の実運用検討編では、開発の実践を通して得られた知見をもとに、実運用でどういった考慮が必要かについて考えます。
OpenAI社が新しく発表したモデル
Open AI社の発表
ChatGPTを提供するOpenAI社は、2025年8月5日に、新たなモデル「gpt-oss-120b」と「gpt-oss-20b」を発表しました。(参考:gpt-oss-120b と gpt-oss-20b Model Card | OpenAI)
これまで広く利用されてきたChatGPTは、WebブラウザやAPIを通じてChatGPTサーバーにアクセスして使用する形態でした。
一方、今回発表されたモデルは、自分のパソコンやサーバーにインストールして利用できる点が大きな特徴です。外部のシステムと通信することなく単独で動作するため、やり取りの内容が外部に送信されることはありません。
この特性により、アプリケーションのセキュリティを重視する必要がある業務向けアプリケーションに適しています。
このような仕組みを持つモデルは「オープンウェイトモデル」と呼ばれています。
OpenAI社では、長らく最新版をオープンウェイトモデルとして公開しない方針を取ってきましたが、今回は公開する方針に切り替えたようです。(参考:オープンウェイトとすべての人のための AI | OpenAI)
公開されたモデルの違い
今回公開された各モデルは、2025年8月21日時点で公開されている最新版「GPT-5」よりも少し古いバージョンと同程度の性能であるようです。
今回公開されたモデルは下記の2つです。
- gpt-oss-120b
- gpt-oss-20b
gpt-oss-120b
gpt-oss-20bと比べて、下記が優れたモデルです。
- より細かい文脈の違いをとらえること
- より複雑なパターンを表現出来ること
- より多様な知識を圧縮して保持できる
このようにgpt-oss-20bよりも回答の品質が高い一方で、円滑に実行するには超ハイエンドなハードウェアが必要となり、一般的なPC(【例】CPU:Intel Core i7、メモリ:16GB、GPU:なし)で実行しようとすると、回答が得られるまでにかなり多くの時間がかかります。
コア推論ベンチマークでは、OpenAI o4-miniとほぼ同等の性能であるようです。
gpt-oss-20b
gpt-oss-120bと比べて、早く回答することを重視したモデルです。
gpt-oss-120bよりも回答の品質は落ちますが、一般的なPC(上記例同様)でもある程度円滑に動作させることができます。
一般的なベンチマークでは、OpenAI o3-miniと同様の性能であるようです。
参考
gpt-oss が登場 オープンウェイトリーズニングモデルの限界を押し広げる gpt-oss-120b と gpt-oss-20b | OpenAI
アプリケーションの実装
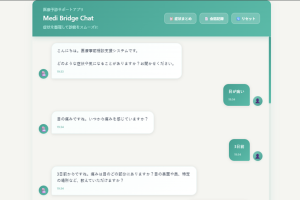
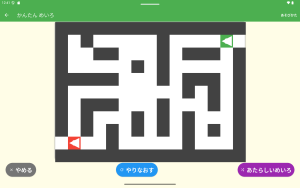
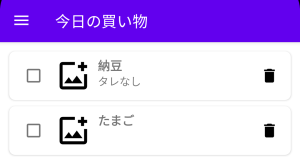
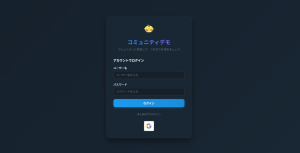
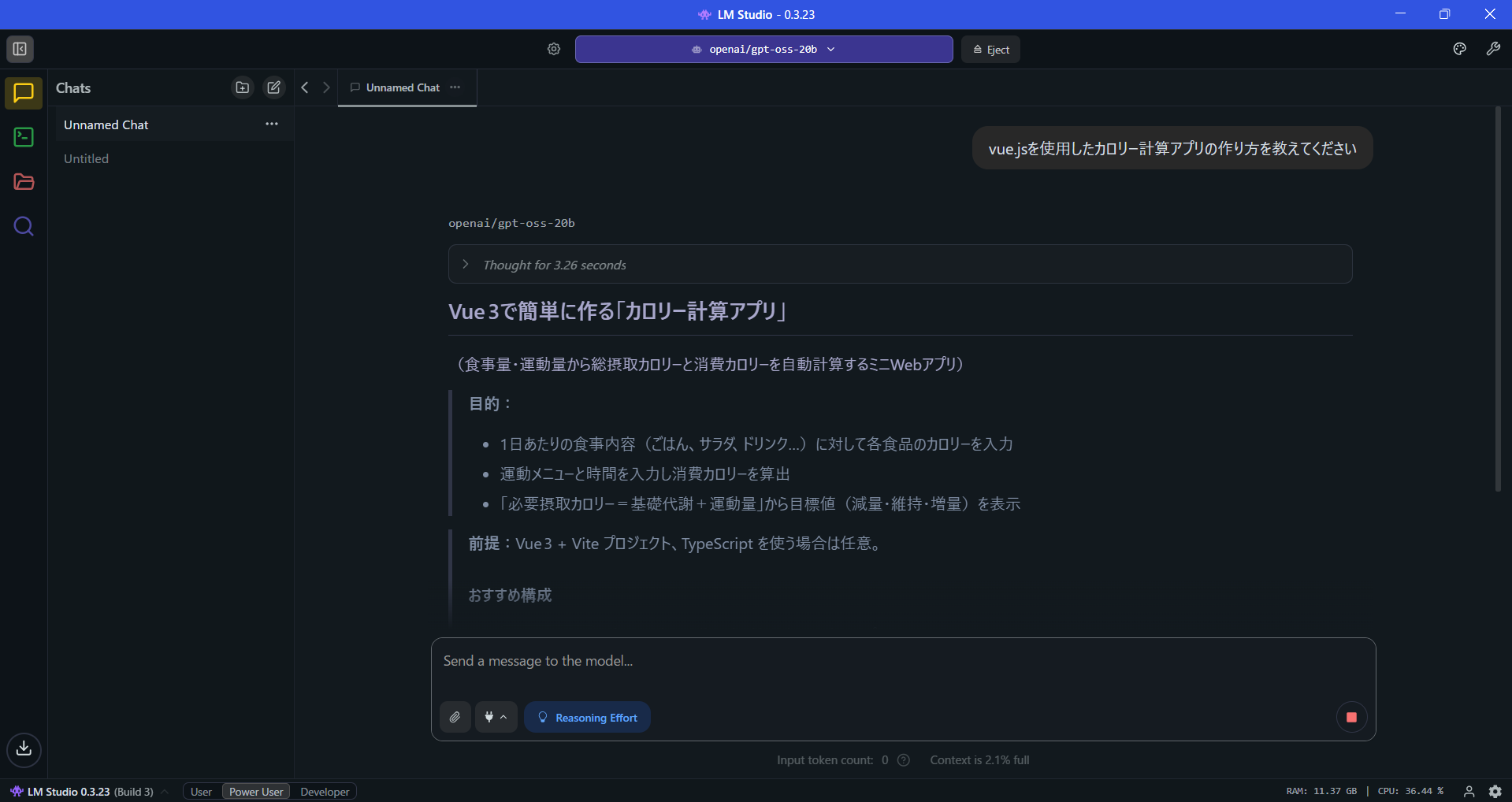
gpt-oss-20bの特徴を掴むために、「カロリー計算アプリケーション」を作ってみました。
モデルの実行用アプリケーションはLM Studioです。
AIの実行には、一般的なPCよりもスペックの高い開発用PCで実施しました。
- CPU:13th Gen Intel(R) Core(TM) i5-13600K(3.50GHz)
- メモリ:64GB
- グラフィックカード:NVIDIA GeForce RTX 4070(専用GPUメモリ:12GB)※CUDA設定ON
以下の動画のようなアプリが完成しました。
実装を終えた所感
今回のアプリケーションはVue.jsで実装し、実装作業は8時間程度でした。
作業はChatGPTで開発を行う場合と同じで、プログラムの書き方とエラーの解消方法をAIに質問して、有効な回答をプログラムに適用する方法を取りました。
全体として、gpt-oss-20bの回答品質には満足で、他の記事で公開しているアプリ開発(Webブラウザ版のChatGPTやGithub Copilotを利用)と同様に進めることができました。
ただし、回答速度の面ではクラウド版に比べてかなり遅く、今回実行したPCのスペックでは、リクエストを渡してから回答が出力されるまでに5分以上の時間がかかることも多くありました。
Webブラウザ版の回答速度重視のモデルならば気づいたことをどんどん質問できますが、今回の回答速度では次の質問をするまでにしばらく待たなければならず、Webブラウザ版のモデルに比べて開発時のストレスは高めでした。
まとめ
gpt-oss-20bでもアプリケーション実装の助けになるレベルの回答品質が得られることがわかりました。
ただし、回答速度面では今回利用したPCでは課題があり、ユーザが快適と感じるような回答速度を実現するには、さらに高いスペックのハードウェアを準備する必要がありそうです。
次回は、実際にオープンウェイトモデルを業務運用する際に検討するべき事項について考えていきます。
実運用検討編はこちらです。